快速定位业务代码性能问题

应用的性能对用户体验至关重要,如何找出业务代码中的性能瓶颈并加以解决呢?简单来说,它指的是你的应用在运行过程中出现的性能瓶颈点,也就是导致应用运行变慢的核心问题。这些瓶颈点通常可以归结为一些耗时的操作、资源占用过多、算法未优化等等。解决这些性能问题可以让你的应用变得更快速、更高效。
通过在线Demo故障注入平台,注入例如
运行额外任务抢占Pod可用的CPU资源运行额外任务抢占Pod可用的memroy资源增加POD FullGC频率增加处理每个请求的CPU消耗等故障来模拟真实环境中代码问题造成的性能问题。
本指南将展示如何使用 Kindling-OriginX 对业务代码中的性能问题进行快速定位,同时与传统方式进行简单对比。
传统方式
传统方式中主要通过各类 APM 工具,日志分析工具,性能压测等方法来发现业务代码中的性能问题。
性能分析工具
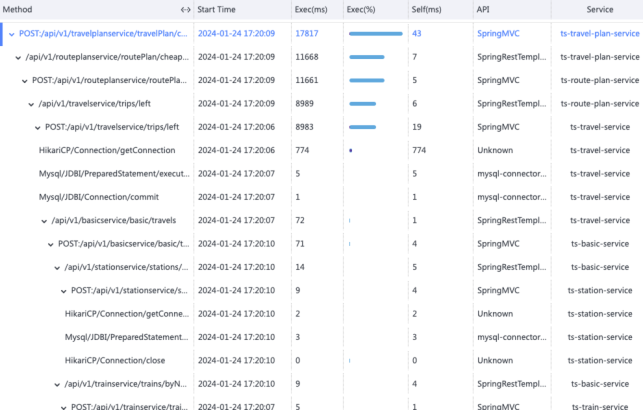
通过大量Tracing、Log、Metrics数据,再结合JVM、系统日志、中间件日志等各类数据,人工汇总分析定位,工作量极大,难以快速完成。以下图为例,Trace数据及调用栈既多又杂,实际处理中无从下手,且难以和Log、Metrics数据协同分析。
专家经验
往往根据经验或其他主观判断,采用代码Review的方式,逐个对性能代码就行优化,往往处理周期长且几乎完全依赖个别专家主观判断。
日志分析
通过长时间多轮次的日志打点追踪,记录跟踪性能问题点,通过日志分析与比对定位性能瓶颈。经常容易丢失故障现场,既需要多种相关软件支持,又需要有相关经验的技术专家,以下图为例大量日志分析也需要大量时间和人力。
压测分析
尽可能构建真实的使用环境,进行压力测试,查找并分析代码中可能存在的性能问题。压测环境难以和生产环境完成一致,不同的压测手段也导致其有很大的局限性。
传统方式中业务代码性能问题难以排查主要是由于缺乏可见性、依赖专家能力、复杂的应用架构、限制性调试工具以及不可重现性问题等因素的综合作用。为了更高效地排查业务代码性能问题,需要有现代化的方法和工具,提供自动化和全局化的支持,帮助开发人员更快地定位和解决问题。
使用Kindling-OriginX
Kindling-OriginX 对于发生在业务代码中的性能问题提供自动化、零侵入、高效便捷、极低性能损耗的解决方案。
针对每一条 Tracing 自动化分析
- 分类统计当下故障服务情况,清晰直观发现性能问题点。
- 聚合单个服务故障报告,聚焦重点问题。
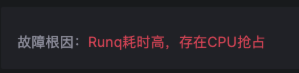
智能化生成可解释的故障根因报告
-
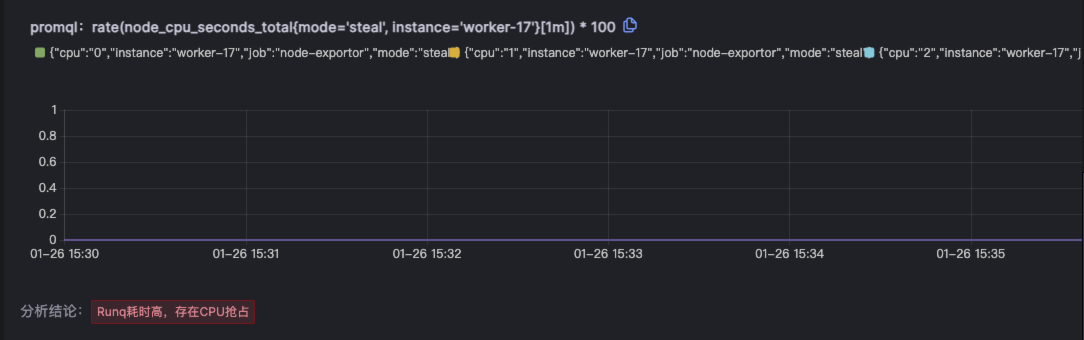
简明扼要给出可解释的根因报告,任何人都能据此高效定位导致性能问题的原因。例如本例中给出根因是对应节点的Runq耗时高,存在CPU抢占。
-
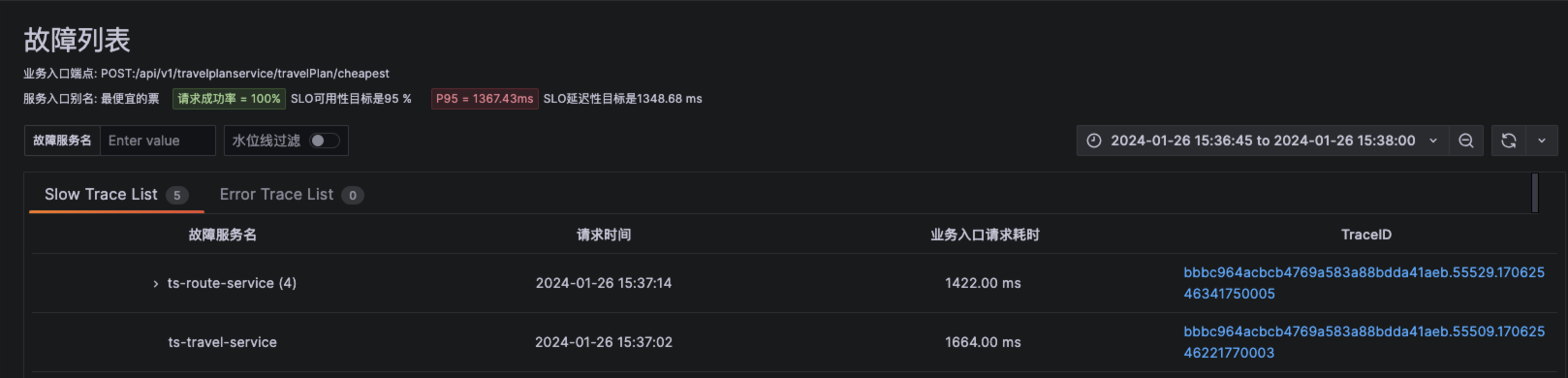
报告包含 Trace 信息,描述、时间、耗时、TraceID等基本信息。

-
报告对节点链路调用情况及耗时数据进行详细对比分析。
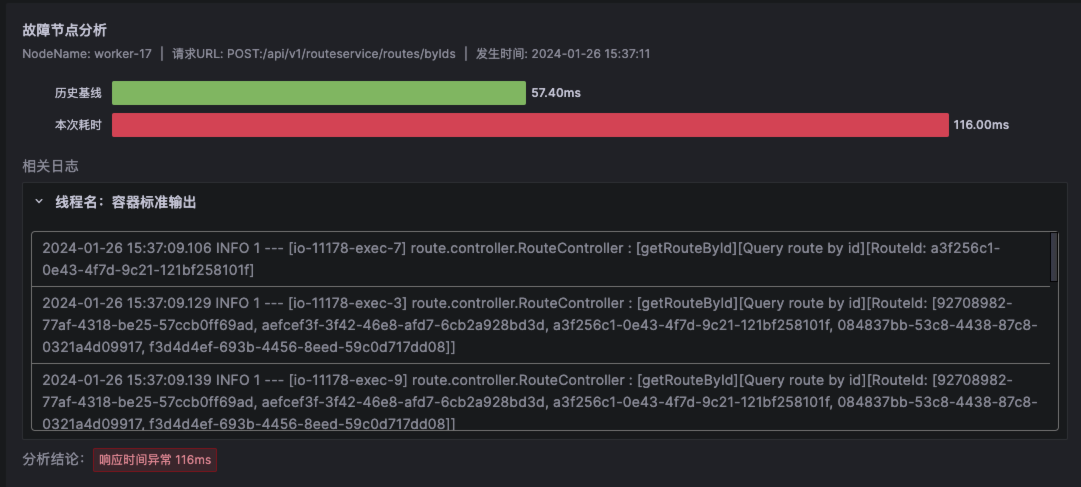
-
提供节点详情、Trace 耗时情况对比及该时段对应日志。本例中结合给出的故障根因和问题时段的日志,即可确定性能问题所在位置。
-
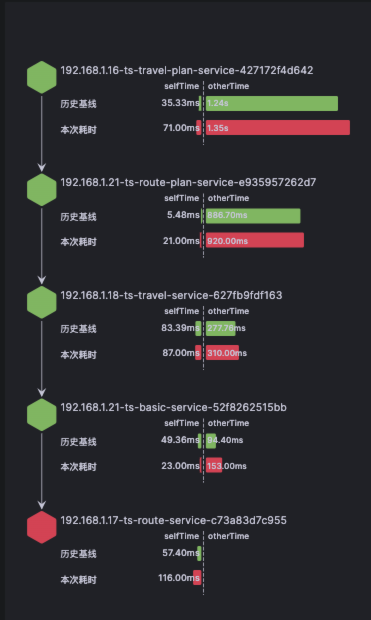
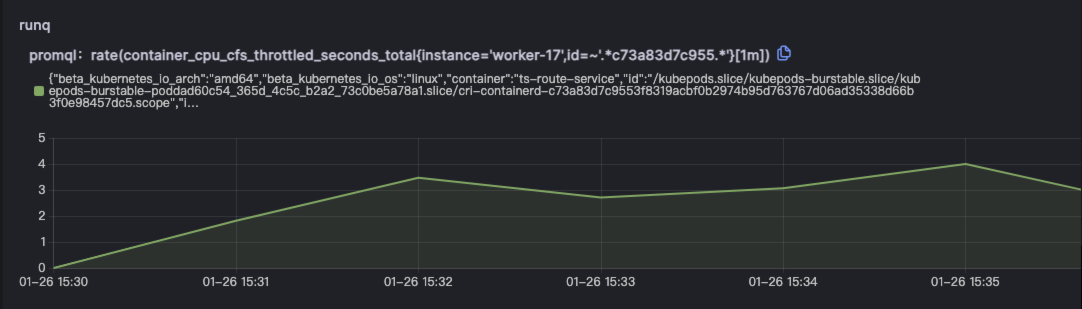
提供各层级分段调用数据及单独的历史基线数据,使用户能够对代码执行的每一步都能了如指掌,通过耗时分析对问题方向提供明确指引。例如本例中runq耗时明显高于历史基线水平。

-
提供影响各条Trace数据的核心指标详情,帮助用户聚焦关键指标。报告中包含根因推导过程的详细数据及指标,既可还原推导过程又可帮助还原现场。例如本例中runq耗时高,则会针对runq相关的指标进行下钻分析。
Kindling-OriginX 相较于传统工具和方法,能够自动化快速定位业务代码造成的性能问题,并智能化生成可解释的故障根因报告。
通过在线Demo)故障注入平台,注入例如 运行额外任务抢占Pod可用的CPU资源 运行额外任务抢占Pod可用的memroy资源 增加POD FullGC频率 增加处理每个请求的CPU消耗 等故障来模拟真实环境中代码问题造成的性能问题。